There’s an awful lot of interesting ideas to unpack in the Nineteenth-Century Serials Edition (ncse) resource mentioned in a previous posting.
For a start, there is novel to addition to showing results by showing the image reproduction for a search results as well as the OCR’d transcription.
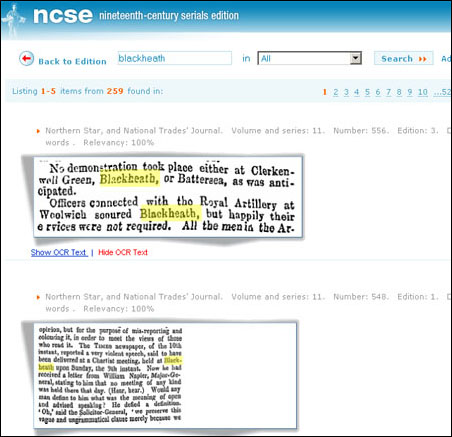
There’s the whole range of partners involved in such a website, indicative of who needs to be involved to run an ambitious digitisation project.

And the related conference brought up a whole host of intellectual questions related to integrating the work into scholarly research.
But what is most interesting is the project’s attempts to automatically give subject keywords to articles within their resource by using natural language processing.

Each article in their website has been processed in two ways. Firstly, to extract persons, places, institutions from the complete data; and secondly to create subject terms (e.g. Arts & Crafts or Emotional Actions, States & Processes ) which relate to each of the digitised articles in the collection.
This is handy for users because it bypasses the tyranny of having to use precise search terms to discover particular articles; and it’s useful for the digitiser because they do not have to go through each article individually and make manual decisions about the subject there within.
I’m not sure it completely works as yet (there are some faults in the results and the interface is not intuitive), but this is a brave and valuable step in trying to really exploit the richness of digitised resources, a richness we have not really tapped into yet.
One reply on “Creating Keywords Automatically”
Automatic discovery of keywords is fascinating. Is there any resource on how they did it?